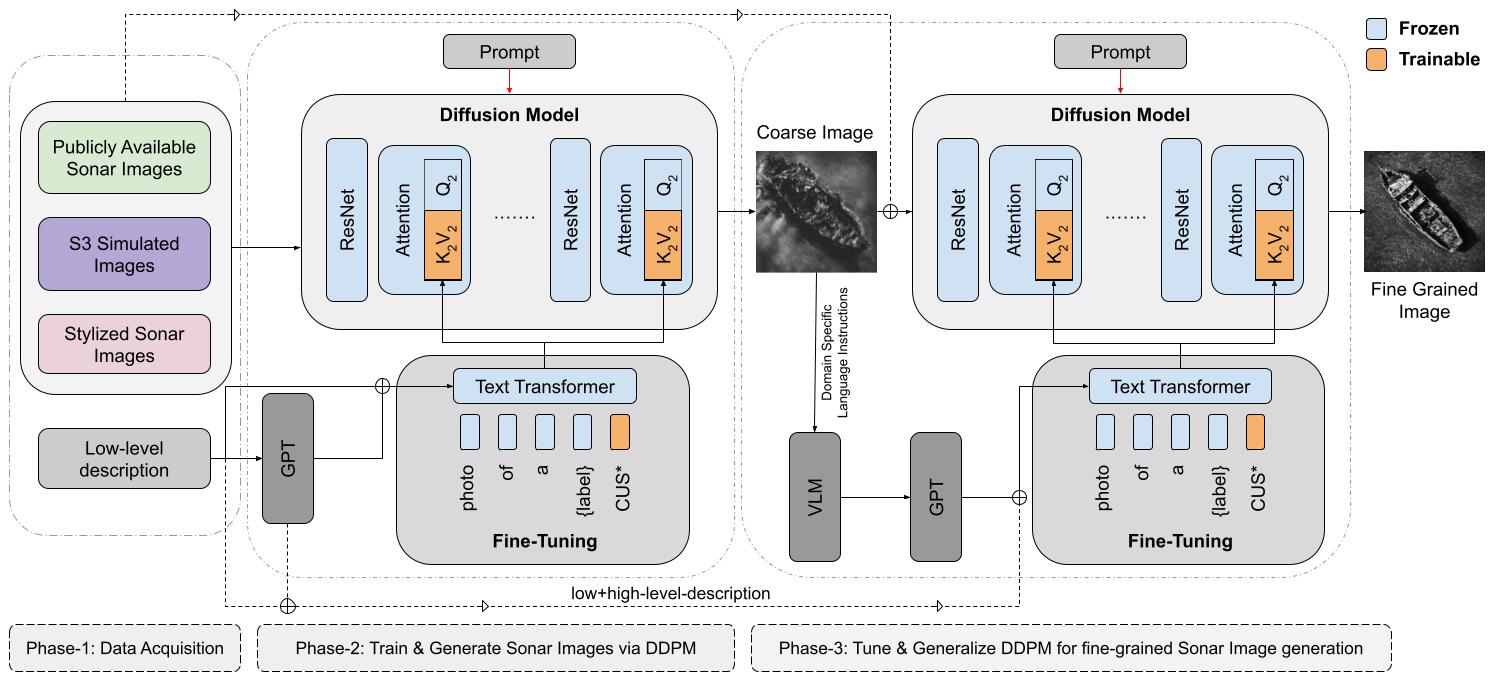
Quick Start
Get started with Synth-SONAR in minutes
Installation
# Clone the repository
git clone https://github.com/Purushothaman-natarajan/Synth-SONAR.git
cd Synth-SONAR
# Create and activate conda environment
conda env create -f environment.yaml
conda activate Synth-SONAR
# Download StableDiffusion weights
# From https://huggingface.co/CompVis/stable-diffusion-v1-4-original
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
Step 1: Style Injection
# Run with default configuration
python run_styleid.py --cnt data/cnt --sty data/sty --gamma 0.75 --T 1.5
# High style fidelity
python run_styleid.py --cnt data/cnt --sty data/sty --gamma 0.3 --T 1.5
Step 2: Fine-Tuning
# Standard Fine-Tuning
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" ./text_to_image/train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--use_ema --resolution=512 --center_crop --random_flip \
--train_batch_size=1 --gradient_accumulation_steps=4 \
--gradient_checkpointing --max_train_steps=5000 \
--learning_rate=1e-05 --output_dir="sd-sonar-model"
Step 3: Inference
from diffusers import StableDiffusionPipeline
import torch
model_path = "path_to_saved_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="A sonar image of an underwater scene").images[0]
image.save("sonar_image.png")
Utility: Create Metadata
python create_metadata(data_to_json).py <image_folder>
Utility: Generate Captions
# Using GPT-3.5 Turbo
python generate_captions_GPT.py <json_file>
# Using LLaMA
python generate_captions_llama.py <jsonl_file> --batch_size 8